Temporal Question Answering for Semi-Structured Tables
About
In semi-structured data, such as Infobox tables, temporal information about entities is common but often challenging for current NLP systems to handle effectively. Our introduction of TempTabQA addresses this by presenting a rich dataset consisting of 11,454 question-answer pairs sourced from 1,208 diverse Wikipedia Infobox tables spanning over 90 distinct domains. The evaluation of leading models in this task reveals a significant gap, with even the best-performing LLMs trailing human performance by more than 13.5 F1 points. Our dataset stands as a robust benchmark, aiming to push the boundaries and improve the temporal reasoning capabilities of NLP models in handling such intricate data structures.
TL;DR: TempTabQA, featuring 11,000+ Q&A pairs sourced from varied Wikipedia Infobox tables, evaluates NLP models' understanding of temporal data. Results indicate top models lag over 13.5 F1 points behind human performance, highlighting the potential to improve models' temporal reasoning
TempTabQA dataset creation procedure
We use Amazon Mechanical Turk (mturk) for data collection and validation. Annotators were presented with a tabular premise (infobox tables) and instructed to write three temporal questions based on the table along with their answers.We provided detailed instructions with illustrative examples using a table and also general principles to bear in mind (refer to template). For each question-answer pair in the development and the test sets, we also got the answers verified by 3 to 6 turkers as shown here (refer to template).
TempTabQA Example
Below is an example from the TempTabQA dataset.

Question 1: When was the most recent time that Roy Emerson won the Australian Open ?
Answer 1: 1969
Question 2: How long did Roy Emerson play in the amateur league before going professional ?
Answer 2: 15 years
Question 3: How old was Roy Emerson when he retired from playing professionally ?
Answer 3: 47 years old
Question 4: What year was Roy Emerson inducted into the International Tennis Hall of Fame ?
Answer 4: 1982
Question 5: Which Grand Slam tournament did Emerson win the 2nd time he won the Davis Cup team competition?
Answer 5: French Open
TempTabQA dataset statistics

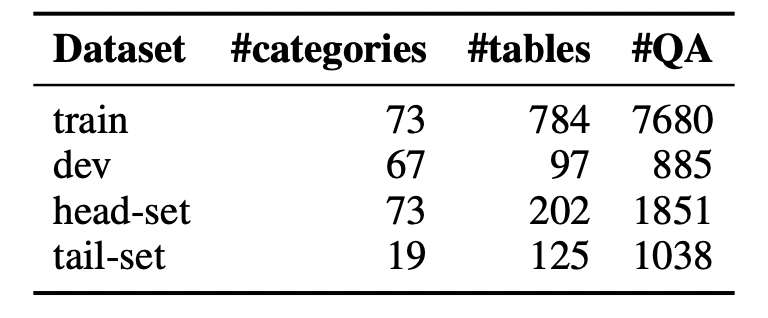
TempTabQA consists of 4 splits (train, dev, head, tail). Head are popular domain, Tail are rare domains
TempTabQA Domain statistics
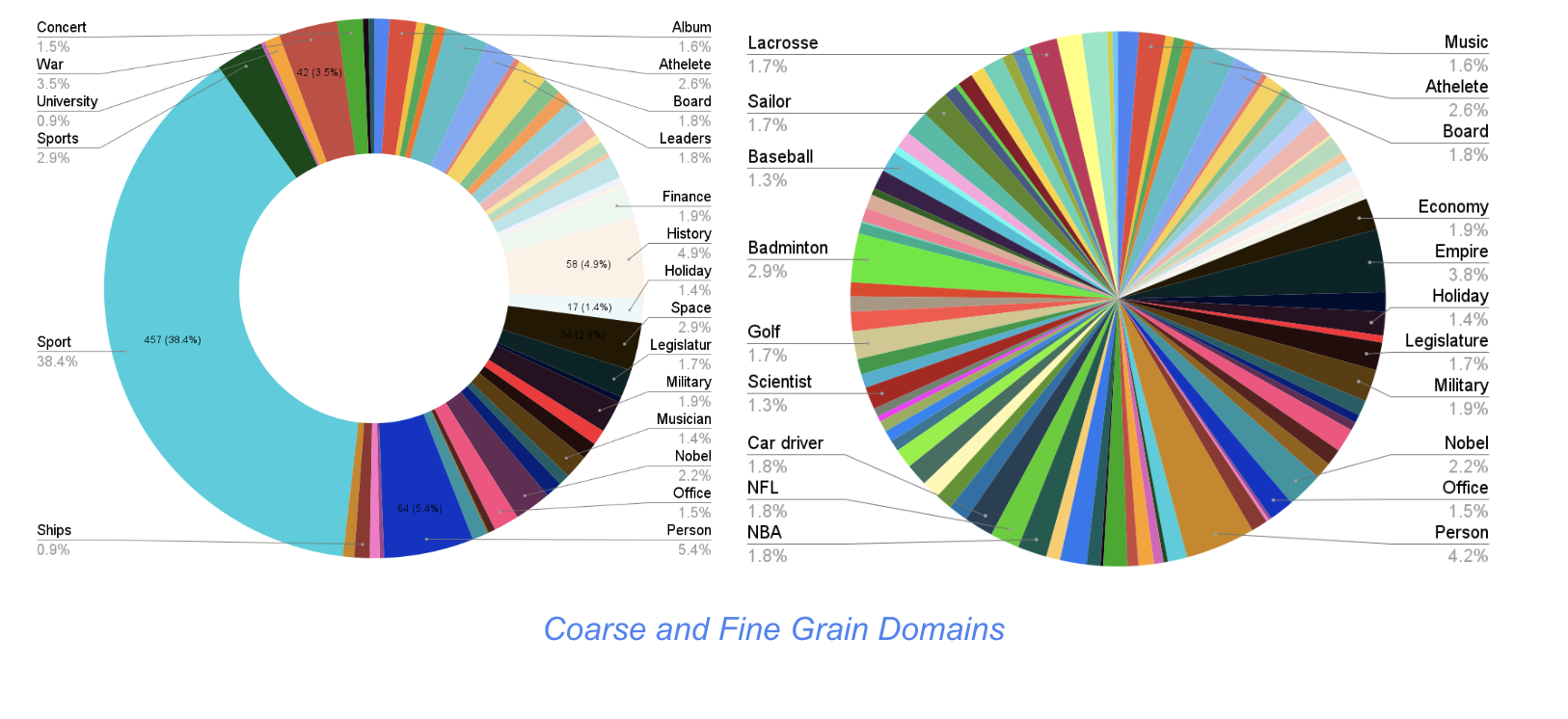
The charts below summarize the different categories that are spanned by our tables. It has over 90 fine grained domains.
TempTabQA dataset analysis
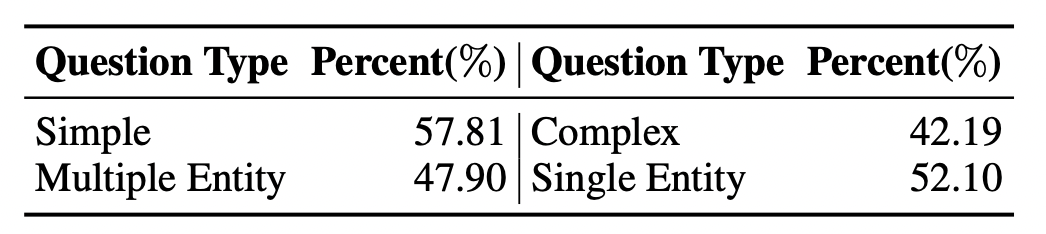
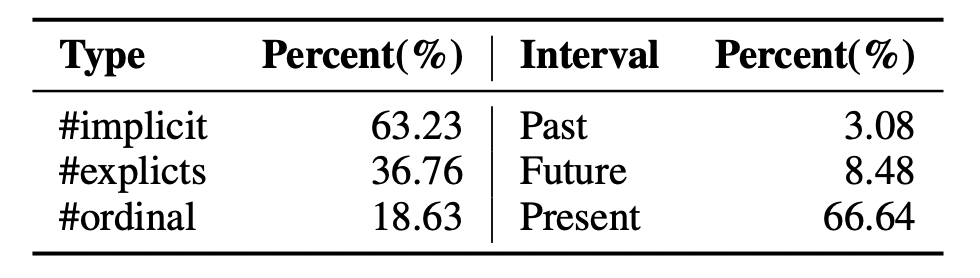
These tables summarise the diversity of our dataset based on the complexity of questions, their nature, and the included functional operation if any and on the type of the entity involved.

Data Validation Statistics
Majority Agreement and Human Accuracy
Exact agreement between annotators
Performance of LLMs
Few shot with chain of thought prompting
Instruction Fine-tune
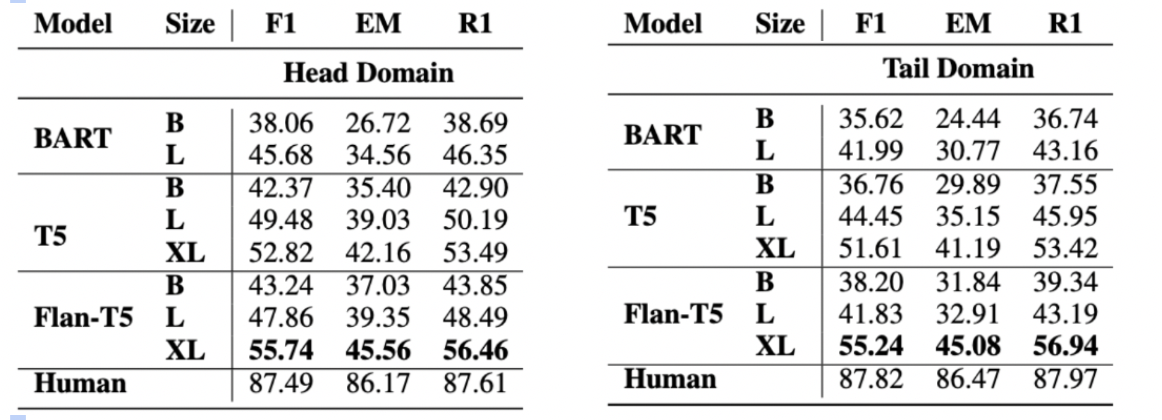
Evaluating recent LLMs on TEMPTABQA dataset, which reveals significant performance gaps as compared to human. Approaches include zero and few shot prompting with/without chain of thought reasoning, converting to knowledge graph representation and inferencing on that, Instruction finetuning on LLMs to evaluate their performance on our dataset.
People
The TempTabQA dataset is prepared by the following people:






Citation
Please cite our paper as below if you use the TempTabQA dataset.
@inproceedings{gupta-etal-2023-temptabqa,
title = "{T}emp{T}ab{QA}: Temporal Question Answering for Semi-Structured Tables",
author = "Gupta, Vivek and
Kandoi, Pranshu and
Vora, Mahek and
Zhang, Shuo and
He, Yujie and
Reinanda, Ridho and
Srikumar, Vivek",
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.emnlp-main.149",
pages = "2431--2453",
abstract = "Semi-structured data, such as Infobox tables, often include temporal information about entities, either implicitly or explicitly. Can current NLP systems reason about such information in semi-structured tables? To tackle this question, we introduce the task of temporal question answering on semi-structured tables. We present a dataset, TEMPTABQA, which comprises 11,454 question-answer pairs extracted from 1,208 Wikipedia Infobox tables spanning more than 90 distinct domains. Using this dataset, we evaluate several state-of-the-art models for temporal reasoning. We observe that even the top-performing LLMs lag behind human performance by more than 13.5 F1 points. Given these results, our dataset has the potential to serve as a challenging benchmark to improve the temporal reasoning capabilities of NLP models.",
}Acknowledgement
The authors express their gratitude to Bloomberg’s AI Engineering team, particularly Edgar Meij and Prabhanjan Kambadur, for their invaluable feed- back and guidance. We are also thankful for the valuable insights provided by Ellen Riloff, Dan Roth, and the Utah NLP group. Special thanks to Dibyakanti Kumar and Manasvi Kundalia for their contributions. Vivek Gupta acknowledges the support received from Bloomberg’s Data Science Ph.D. Fellowship and the Cognitive Computation Group at the University of Pennsylvania. This work is partially supported by NSF grants #1801446, #1822877, #2007398 and #2129111. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies of any government agency. Lastly, we extend our appreciation to the reviewing team for their insightful comments.